Bulk RNA-seq to Single RNA-seq¶
Bulk2Single is used for bulk RNA-seq deconvolution. We extracted the beta-VAE part of the Bulk2Space algorithm and constructed an algorithm that can deconvolute from Bulk RNA-seq to Single Cell RNA-seq. In addition, we have redesigned the input and output of the data so that it can be more compatible with the analysis conventions in the Python environment.
Paper: De novo analysis of bulk RNA-seq data at spatially resolved single-cell resolution
Code: https://github.com/ZJUFanLab/bulk2space
Colab_Reproducibility:https://colab.research.google.com/drive/1He71hAyeAv1DHQyXUlxtoJ4QvwZwW7I0?usp=sharing
This tutorial walks through how to read, set-up and train the model from bulk RNA-seq and reference scRNA-seq data. We use the pdac datasets as example
import scanpy as sc
import omicverse as ov
import matplotlib.pyplot as plt
ov.plot_set()
____ _ _ __
/ __ \____ ___ (_)___| | / /__ _____________
/ / / / __ `__ \/ / ___/ | / / _ \/ ___/ ___/ _ \
/ /_/ / / / / / / / /__ | |/ / __/ / (__ ) __/
\____/_/ /_/ /_/_/\___/ |___/\___/_/ /____/\___/
Version: 1.6.3, Tutorials: https://omicverse.readthedocs.io/
loading data¶
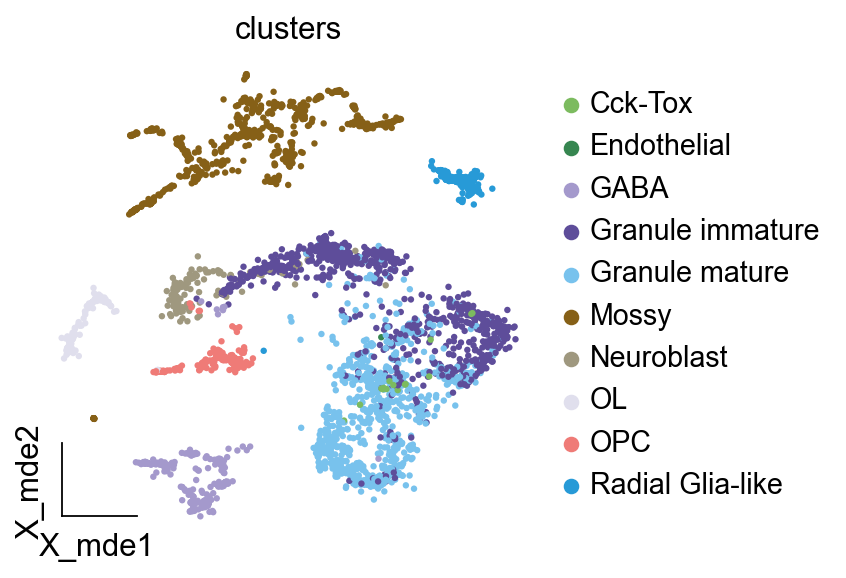
For illustration, we apply differential kinetic analysis to dentate gyrus neurogenesis, which comprises multiple heterogeneous subpopulations.
We utilized single-cell RNA-seq data (GEO accession: GSE95753) obtained from the dentate gyrus of the hippocampus in rats, along with bulk RNA-seq data (GEO accession: GSE74985).
bulk_data=ov.read('data/GSE74985_mergedCount.txt.gz',index_col=0)
bulk_data=ov.bulk.Matrix_ID_mapping(bulk_data,'genesets/pair_GRCm39.tsv')
bulk_data.head()
| dg_d_1 | dg_d_2 | dg_d_3 | dg_v_1 | dg_v_2 | dg_v_3 | ca4_1 | ca4_2 | ca4_3 | ca3_d_1 | ... | ca3_v_3 | ca2_1 | ca2_2 | ca2_3 | ca1_d_1 | ca1_d_2 | ca1_d_3 | ca1_v_1 | ca1_v_2 | ca1_v_3 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Gm12150 | 0 | 2 | 0 | 11 | 0 | 9 | 72 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Mir219a-2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Hspd1 | 1418 | 685 | 1404 | 3073 | 2316 | 1945 | 7724 | 8255 | 6802 | 4956 | ... | 8154 | 7104 | 5854 | 7508 | 5322 | 6172 | 5199 | 1865 | 1253 | 2298 |
| Crhbp | 0 | 0 | 0 | 31 | 17 | 32 | 0 | 0 | 0 | 29 | ... | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Gm11735 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
5 rows × 24 columns
import anndata
import scvelo as scv
single_data=scv.datasets.dentategyrus()
single_data
AnnData object with n_obs × n_vars = 2930 × 13913
obs: 'clusters', 'age(days)', 'clusters_enlarged'
uns: 'clusters_colors'
obsm: 'X_umap'
layers: 'ambiguous', 'spliced', 'unspliced'
Cell Fraction calculation¶
We can now set up the Bulk2Single object, which will ensure everything the model needs is in place for training. We need to specify the cell type of the scRNA-seq to deconvolute the Bulk RNA-seq. And specify the number of marker genes for each cell type for training.
if you set gpu=-1, it will use CPU to configure the VAE model.
model=ov.bulk2single.Bulk2Single(bulk_data=bulk_data,single_data=single_data,
celltype_key='clusters',bulk_group=['dg_d_1','dg_d_2','dg_d_3'],
top_marker_num=200,ratio_num=1,gpu=0)
Here, we improved the estimation of cell proportions in Bulk2space, and we eliminated the regression estimation used by the original authors, which typically results in a large bias in proportions, as confirmed in our analysis. We introduced TAPE, This model is able to accurately deconvolve bulk RNA-seq data into cell fractions and predict cell-type-specific gene expression at cell- type level based on scRNA-seq data.
Code: https://github.com/poseidonchan/TAPE
CellFractionPrediction=model.predicted_fraction()
Reading single-cell dataset, this may take 1 min
Reading dataset is done
Normalizing raw single cell data with scanpy.pp.normalize_total
Generating cell fractions using Dirichlet distribution without prior info (actually random)
RANDOM cell fractions is generated
You set sparse as True, some cell's fraction will be zero, the probability is 0.5
Sampling cells to compose pseudo-bulk data
Sampling is done
Reading training data
Reading is done
Reading test data
Reading test data is done
Using counts data to train model
Cutting variance...
Finding intersected genes...
Intersected gene number is 12227
Scaling...
Using minmax scaler...
training data shape is (5000, 12227)
test data shape is (24, 12227)
train model256 now
train model512 now
train model1024 now
Training of Scaden is done
Predicted Total Cell Num: 2457.268449380651
CellFractionPrediction.head()
| Astrocytes | Cajal Retzius | Cck-Tox | Endothelial | GABA | Granule immature | Granule mature | Microglia | Mossy | Neuroblast | OL | OPC | Radial Glia-like | nIPC | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| dg_d_1 | 0.004780 | 0.003839 | 0.004187 | 0.002460 | 0.005536 | 0.527208 | 0.393742 | 0.005203 | 0.028935 | 0.004639 | 0.007397 | 0.005216 | 0.002961 | 0.003898 |
| dg_d_2 | 0.005013 | 0.002877 | 0.003001 | 0.002407 | 0.004481 | 0.508747 | 0.413222 | 0.004478 | 0.032327 | 0.006355 | 0.007488 | 0.004283 | 0.002102 | 0.003218 |
| dg_d_3 | 0.003915 | 0.002676 | 0.002945 | 0.002558 | 0.005772 | 0.479360 | 0.446842 | 0.004949 | 0.026702 | 0.006624 | 0.008542 | 0.004052 | 0.002157 | 0.002908 |
| dg_v_1 | 0.003247 | 0.002842 | 0.003309 | 0.001613 | 0.010134 | 0.539566 | 0.347792 | 0.002481 | 0.063813 | 0.006122 | 0.008335 | 0.005785 | 0.002116 | 0.002846 |
| dg_v_2 | 0.004015 | 0.003188 | 0.003747 | 0.002137 | 0.010382 | 0.523644 | 0.362331 | 0.002693 | 0.056484 | 0.009367 | 0.008487 | 0.007403 | 0.002478 | 0.003644 |
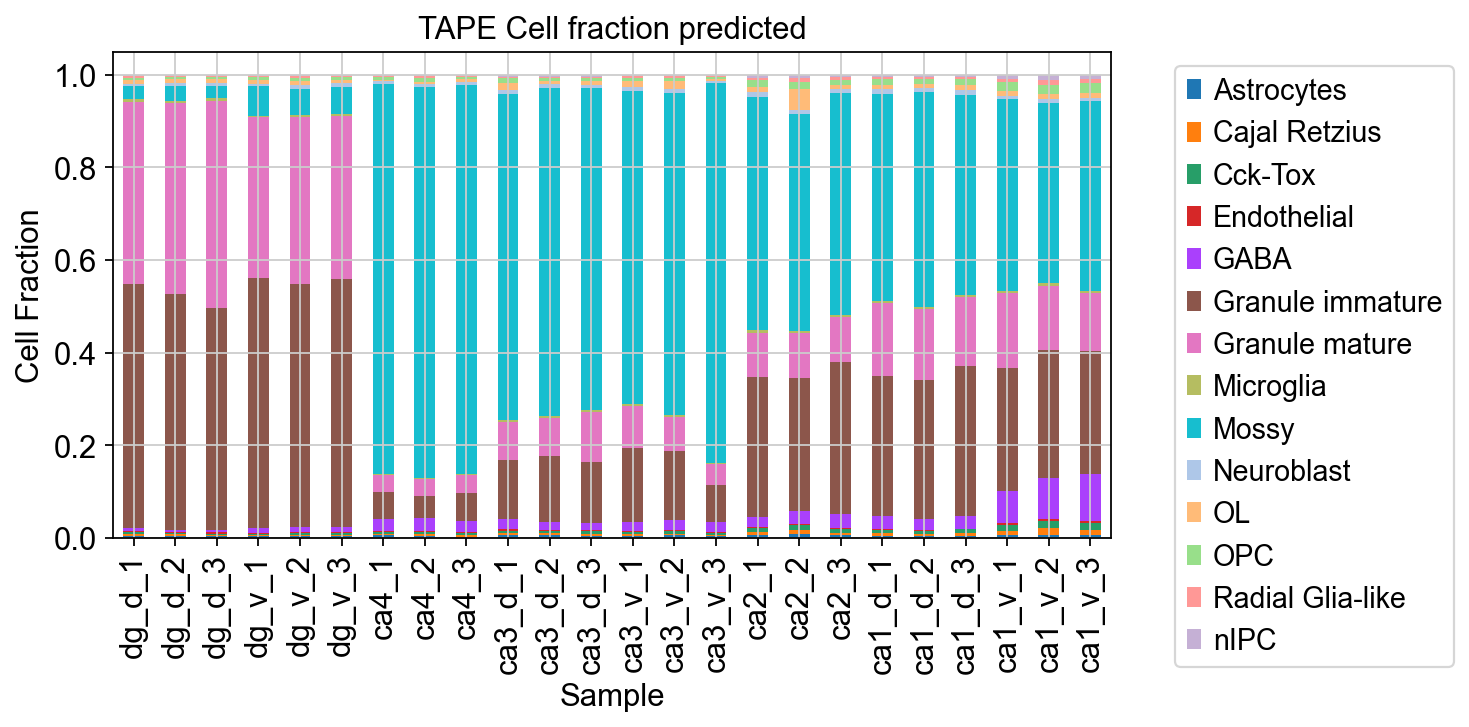
We used stacked histograms to visualize the cellular proportions for each of the samples
ax = CellFractionPrediction.plot(kind='bar', stacked=True, figsize=(8, 4))
ax.set_xlabel('Sample')
ax.set_ylabel('Cell Fraction')
ax.set_title('TAPE Cell fraction predicted')
plt.legend(bbox_to_anchor=(1.05, 1),ncol=1,)
plt.show()
Bulk2single training¶
Preprocess the single-cell RNA-seq and bulk RNA-seq¶
After obtaining the cell proportions for each sample, we also wanted to obtain single-cell data for the samples, where we used beta-VAE to predict the cells in the Bulk, and we first preprocessed the data.
The groups are [‘dg_d_1’, ‘dg_d_2’, ‘dg_d_3’], which represent the sample DG granule cell
model.bulk_preprocess_lazy()
model.single_preprocess_lazy()
model.prepare_input()
......drop duplicates index in bulk data
......deseq2 normalize the bulk data
......log10 the bulk data
......calculate the mean of each group
......normalize the single data
normalizing counts per cell
finished (0:00:00)
......log1p the single data
......prepare the input of bulk2single
...loading data
Trainging the VAE model¶
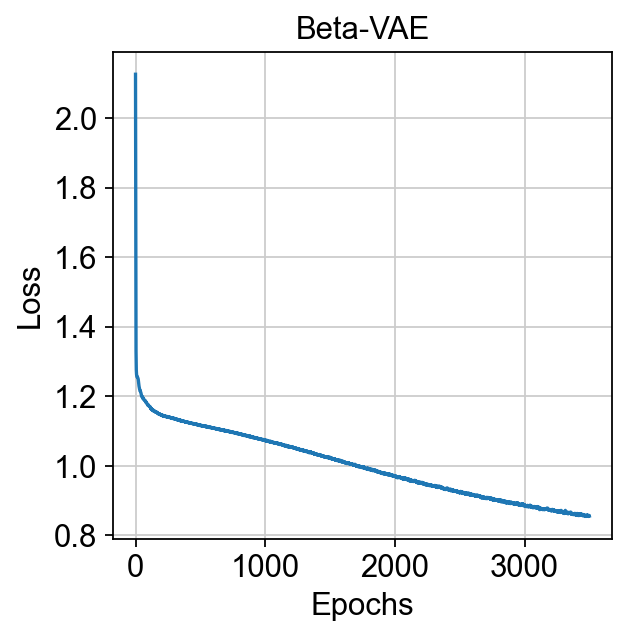
We started training the VAE model to generate single-cell data, a process that took roughly 3 hours on the CPU and only 10 minutes on the GPU.
Note
the default max epochs is set to 3500, but in practice Bulk2Single stops early once the model converges, which rarely requires that many, especially for large datasets.(We can set the patience to control the stop steps)
vae_net=model.train(
batch_size=512,
learning_rate=1e-4,
hidden_size=256,
epoch_num=3500,
vae_save_dir='data/bulk2single/save_model',
vae_save_name='dg_vae',
generate_save_dir='data/bulk2single/output',
generate_save_name='dg')
...begin vae training
min loss = 0.8544222712516785
...vae training done!
...save trained vae in data/bulk2single/save_model/dg_vae.pth.
We can plot the vae loss use a simple method named plot_loss
model.plot_loss()
(<Figure size 320x320 with 1 Axes>,
<AxesSubplot: title={'center': 'Beta-VAE'}, xlabel='Epochs', ylabel='Loss'>)
We can also load our previously trained model directly
#model.load_fraction('dg_vae_cell_target_num.pkl')
#model.bulk_preprocess_lazy()
#model.single_preprocess_lazy()
#model.prepare_input()
vae_net=model.load('data/bulk2single/save_model/dg_vae.pth')
......drop duplicates index in bulk data
......deseq2 normalize the bulk data
......log10 the bulk data
......calculate the mean of each group
......normalize the single data
normalizing counts per cell
finished (0:00:00)
......log1p the single data
......prepare the input of bulk2single
...loading data
loading model from data/bulk2single/save_model/dg_vae.pth
Now, we can generate an Bulk2Single deconvoluted scRNA-seq matrix from our model.
generate_adata=model.generate()
generate_adata
...generating
generated done!
AnnData object with n_obs × n_vars = 4907 × 12953
obs: 'clusters'
There is a lot of noise in our directly generated single-cell data, and we need to filter the noisy cells.
generate_adata=model.filtered(generate_adata,leiden_size=25)
generate_adata
extracting highly variable genes
finished (0:00:00)
--> added
'highly_variable', boolean vector (adata.var)
'means', float vector (adata.var)
'dispersions', float vector (adata.var)
'dispersions_norm', float vector (adata.var)
computing PCA
Note that scikit-learn's randomized PCA might not be exactly reproducible across different computational platforms. For exact reproducibility, choose `svd_solver='arpack'.`
on highly variable genes
with n_comps=100
finished (0:00:02)
computing neighbors
finished: added to `.uns['neighbors']`
`.obsp['distances']`, distances for each pair of neighbors
`.obsp['connectivities']`, weighted adjacency matrix (0:00:02)
running Leiden clustering
finished: found 129 clusters and added
'leiden', the cluster labels (adata.obs, categorical) (0:00:00)
The filter leiden is ['22', '43', '38', '39', '40', '41', '42', '45', '44', '46', '47', '48', '36', '37', '30', '35', '28', '23', '34', '25', '26', '27', '24', '29', '31', '32', '33', '49', '50', '51', '52', '53', '54', '61', '66', '65', '63', '62', '64', '60', '58', '57', '56', '55', '59', '87', '83', '84', '85', '86', '90', '88', '89', '81', '91', '92', '93', '82', '78', '80', '79', '77', '76', '75', '74', '73', '72', '71', '70', '69', '68', '67', '94', '95', '96', '108', '118', '117', '116', '115', '114', '113', '97', '111', '110', '109', '112', '107', '105', '104', '103', '102', '101', '100', '99', '98', '106', '122', '124', '123', '119', '121', '120', '125', '126', '127', '128']
View of AnnData object with n_obs × n_vars = 3591 × 1529
obs: 'clusters', 'leiden'
var: 'highly_variable', 'means', 'dispersions', 'dispersions_norm', 'mean', 'std'
uns: 'hvg', 'pca', 'neighbors', 'leiden'
obsm: 'X_pca'
varm: 'PCs'
obsp: 'distances', 'connectivities'
visualizing and analyzing the correlation¶
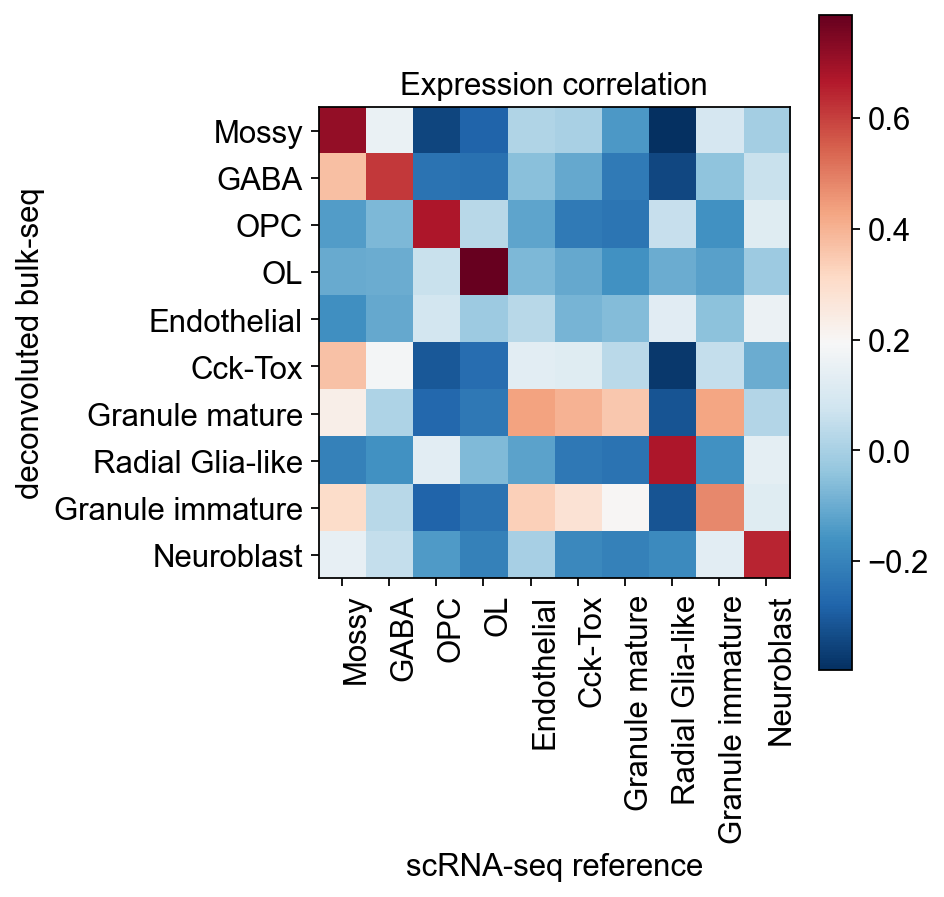
We need to test the characteristics of the generated single cell RNA-seq and the correlation with the reference scRNA-seq. Here, we calculated the correlation between the cell type of the reference scRNA-seq and the cell type of the generated scRNA-seq using the Pearson coefficient using the cell type-specific marker of the reference scRNA-seq as an anchor point.
ov.bulk2single.bulk2single_plot_cellprop(generate_adata,celltype_key='clusters')
plt.grid(False)
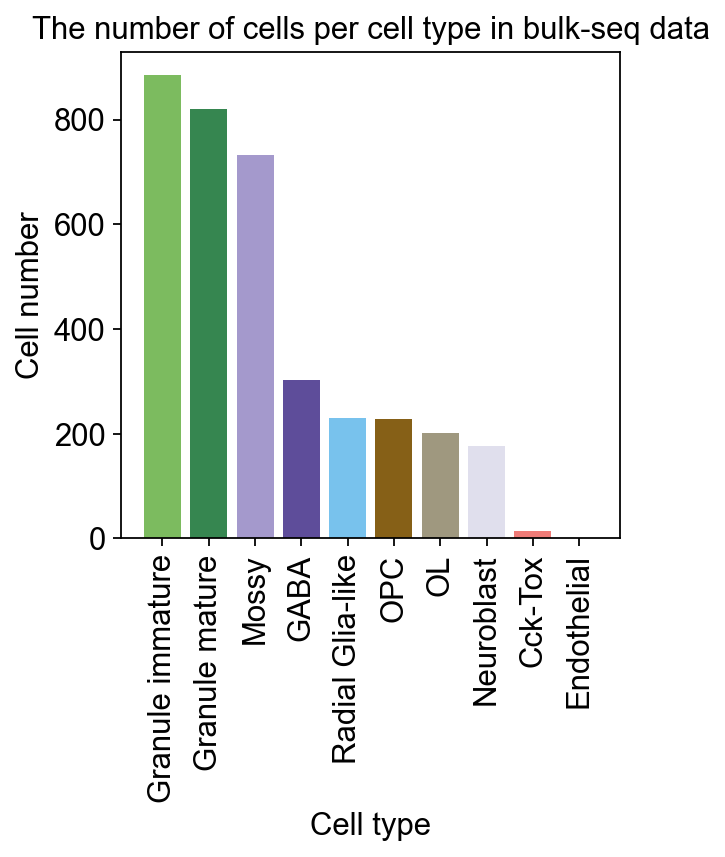
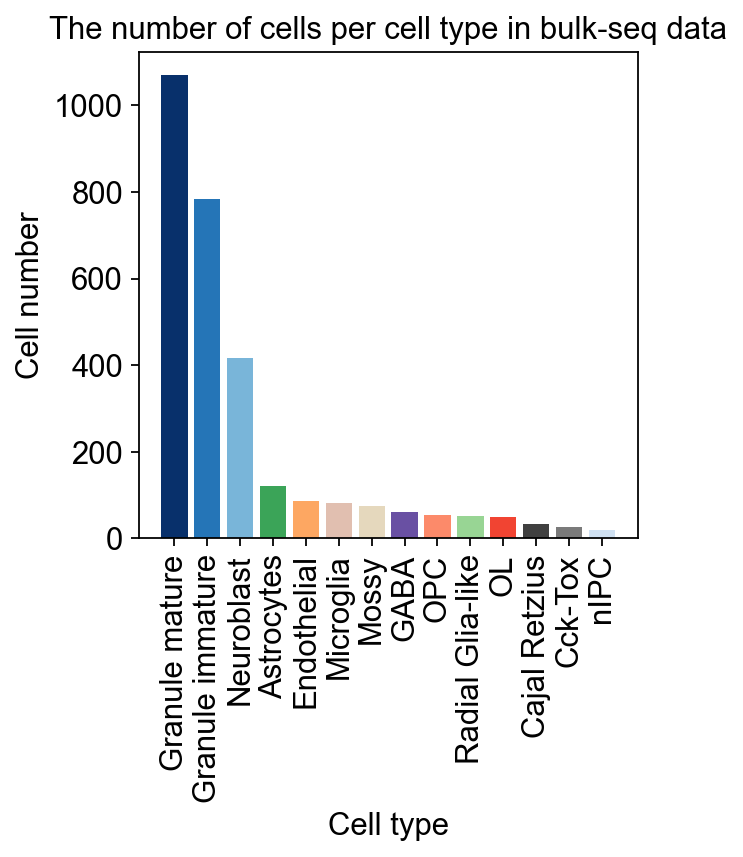
It is very easy for us to compare the proportion of cells between the reference scRNA-seq and generate scRNA-seq
ov.bulk2single.bulk2single_plot_cellprop(single_data,celltype_key='clusters')
plt.grid(False)
ov.bulk2single.bulk2single_plot_correlation(single_data,generate_adata,celltype_key='clusters')
plt.grid(False)
ranking genes
finished: added to `.uns['rank_genes_groups']`
'names', sorted np.recarray to be indexed by group ids
'scores', sorted np.recarray to be indexed by group ids
'logfoldchanges', sorted np.recarray to be indexed by group ids
'pvals', sorted np.recarray to be indexed by group ids
'pvals_adj', sorted np.recarray to be indexed by group ids (0:00:01)
import scanpy as sc
generate_adata.obsm["X_mde"] = ov.utils.mde(generate_adata.obsm["X_pca"])
ov.pl.embedding(generate_adata,basis='X_mde',color=['clusters'],wspace=0.4,
palette=ov.utils.pyomic_palette(),frameon='small')