Clustering space¶
In this tutorial, we will explore how to run the Supervised clustering, unsupervised clustering, and amortized Latent Dirichlet Allocation (LDA) model implementation in omicverse with GaussianMixture,Leiden/Louvain and MiRA.
In scRNA-seq data analysis, we describe cellular structure in our dataset with finding cell identities that relate to known cell states or cell cycle stages. This process is usually called cell identity annotation. For this purpose, we structure cells into clusters to infer the identity of similar cells. Clustering itself is a common unsupervised machine learning problem.
LDA is a topic modelling method first introduced in the natural language processing field. By treating each cell as a document and each gene expression count as a word, we can carry over the method to the single-cell biology field.
Below, we will train the model over a dataset, plot the topics over a UMAP of the reference set, and inspect the topics for characteristic gene sets.
Preprocess data¶
As an example, we apply differential kinetic analysis to dentate gyrus neurogenesis, which comprises multiple heterogeneous subpopulations.
Colab_Reproducibility:https://colab.research.google.com/drive/1d_szq-y-g7O0C5rJgK22XC7uWTUNrYpK?usp=sharing
import omicverse as ov
import scanpy as sc
import scvelo as scv
ov.plot_set(font_path='Arial')
🔬 Starting plot initialization...
Using already downloaded Arial font from: /tmp/omicverse_arial.ttf
Registered as: Arial
🧬 Detecting CUDA devices…
✅ [GPU 0] NVIDIA A40
• Total memory: 44.3 GB
• Compute capability: 8.6
____ _ _ __
/ __ \____ ___ (_)___| | / /__ _____________
/ / / / __ `__ \/ / ___/ | / / _ \/ ___/ ___/ _ \
/ /_/ / / / / / / / /__ | |/ / __/ / (__ ) __/
\____/_/ /_/ /_/_/\___/ |___/\___/_/ /____/\___/
🔖 Version: 1.7.2rc1 📚 Tutorials: https://omicverse.readthedocs.io/
✅ plot_set complete.
import scvelo as scv
adata=scv.datasets.dentategyrus()
adata
AnnData object with n_obs × n_vars = 2930 × 13913
obs: 'clusters', 'age(days)', 'clusters_enlarged'
uns: 'clusters_colors'
obsm: 'X_umap'
layers: 'ambiguous', 'spliced', 'unspliced'
adata=ov.pp.preprocess(adata,mode='shiftlog|pearson',n_HVGs=3000,)
adata.raw = adata
adata = adata[:, adata.var.highly_variable_features]
ov.pp.scale(adata)
ov.pp.pca(adata,layer='scaled',n_pcs=50)
Begin robust gene identification
After filtration, 13264/13913 genes are kept. Among 13264 genes, 13189 genes are robust.
End of robust gene identification.
Begin size normalization: shiftlog and HVGs selection pearson
normalizing counts per cell
The following highly-expressed genes are not considered during normalization factor computation:
['Hba-a1', 'Malat1', 'Ptgds', 'Hbb-bt']
finished (0:00:00)
extracting highly variable genes
--> added
'highly_variable', boolean vector (adata.var)
'highly_variable_rank', float vector (adata.var)
'highly_variable_nbatches', int vector (adata.var)
'highly_variable_intersection', boolean vector (adata.var)
'means', float vector (adata.var)
'variances', float vector (adata.var)
'residual_variances', float vector (adata.var)
Time to analyze data in cpu: 0.458479642868042 seconds.
End of size normalization: shiftlog and HVGs selection pearson
computing PCA
with n_comps=50
finished (0:00:07)
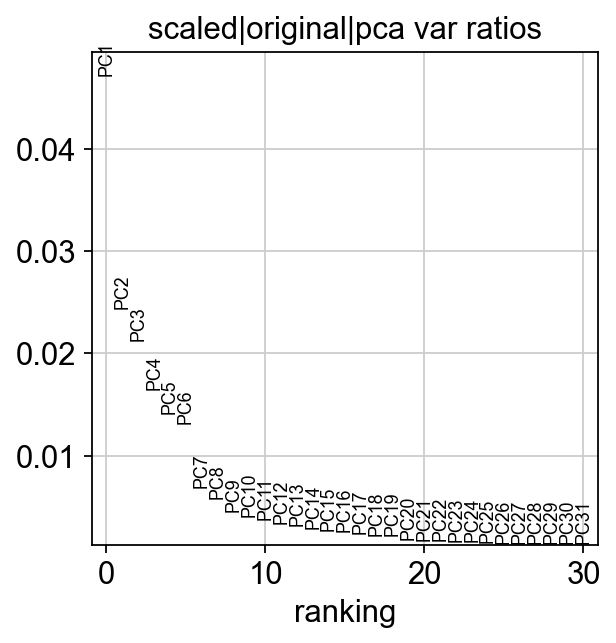
Let us inspect the contribution of single PCs to the total variance in the data. This gives us information about how many PCs we should consider in order to compute the neighborhood relations of cells. In our experience, often a rough estimate of the number of PCs does fine.
ov.utils.plot_pca_variance_ratio(adata)
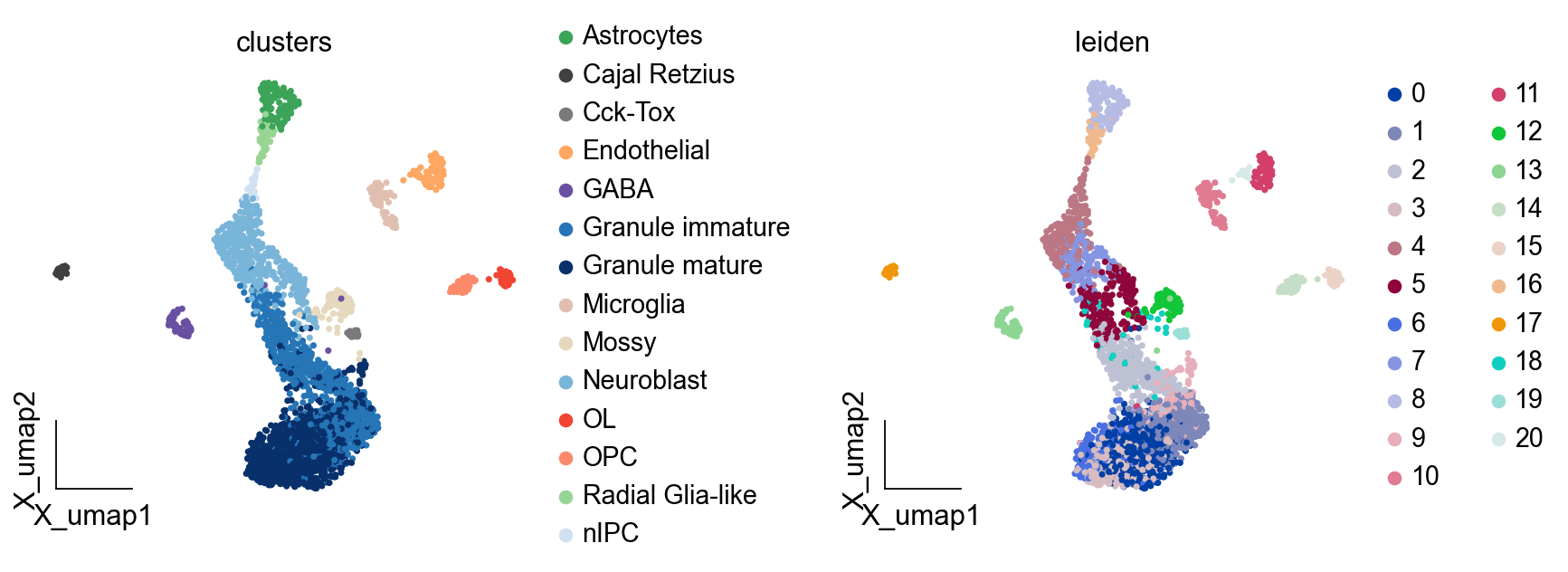
Unsupervised clustering¶
Leiden¶
The Leiden algorithm is as an improved version of the Louvain algorithm which outperformed other clustering methods for single-cell RNA-seq data analysis ([Du et al., 2018, Freytag et al., 2018, Weber and Robinson, 2016]). Since the Louvain algorithm is no longer maintained, using Leiden instead is preferred.
We, therefore, propose to use the Leiden algorithm[Traag et al., 2019] on single-cell k-nearest-neighbour (KNN) graphs to cluster single-cell datasets.
Leiden creates clusters by taking into account the number of links between cells in a cluster versus the overall expected number of links in the dataset.
Here, we set method='leiden' to cluster the cells using Leiden
sc.pp.neighbors(adata, n_neighbors=15, n_pcs=50,
use_rep='scaled|original|X_pca')
ov.utils.cluster(adata,method='leiden',resolution=1)
computing neighbors
finished: added to `.uns['neighbors']`
`.obsp['distances']`, distances for each pair of neighbors
`.obsp['connectivities']`, weighted adjacency matrix (0:00:04)
running Leiden clustering
finished: found 21 clusters and added
'leiden', the cluster labels (adata.obs, categorical) (0:00:00)
ov.pl.embedding(adata,basis='X_umap',
color=['clusters','leiden'],
frameon='small',wspace=0.5)
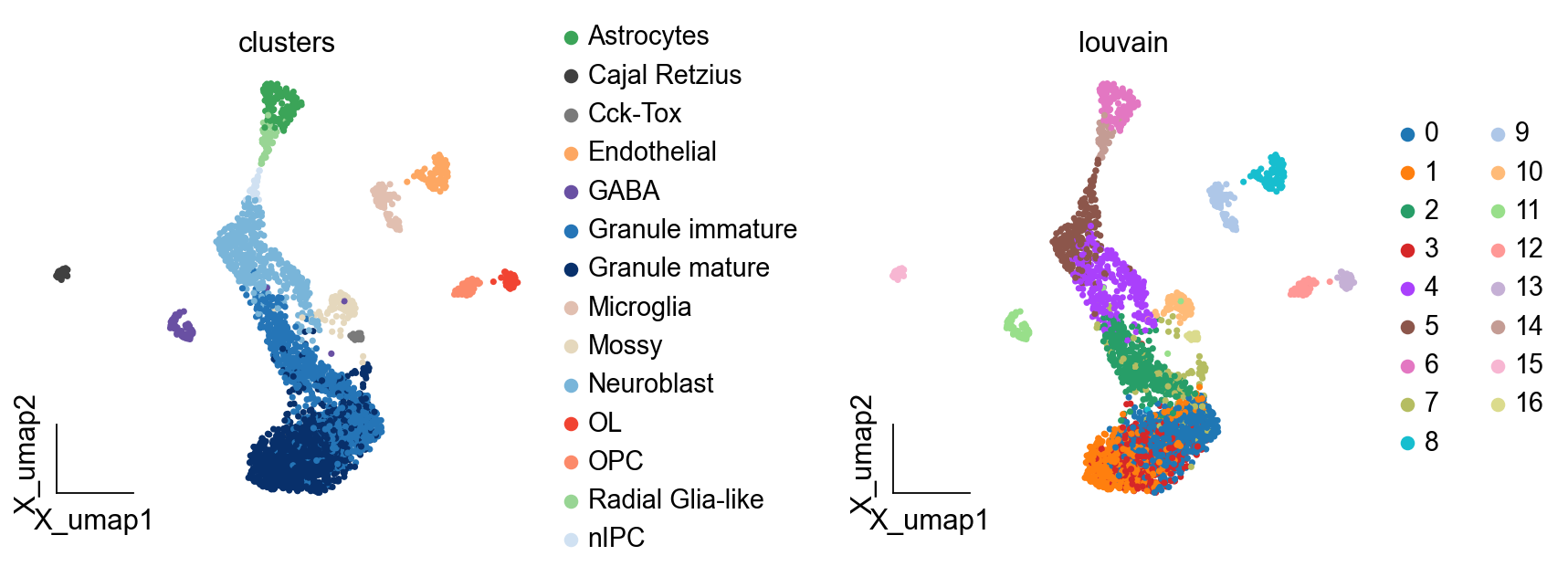
Louvain¶
We can also set method='louvain' to cluster the cells using Louvain
sc.pp.neighbors(adata, n_neighbors=15, n_pcs=50,
use_rep='scaled|original|X_pca')
ov.utils.cluster(adata,method='louvain',resolution=1)
computing neighbors
finished: added to `.uns['neighbors']`
`.obsp['distances']`, distances for each pair of neighbors
`.obsp['connectivities']`, weighted adjacency matrix (0:00:00)
running Louvain clustering
using the "louvain" package of Traag (2017)
finished: found 17 clusters and added
'louvain', the cluster labels (adata.obs, categorical) (0:00:00)
ov.pl.embedding(adata,basis='X_umap',
color=['clusters','louvain'],
frameon='small',wspace=0.5)
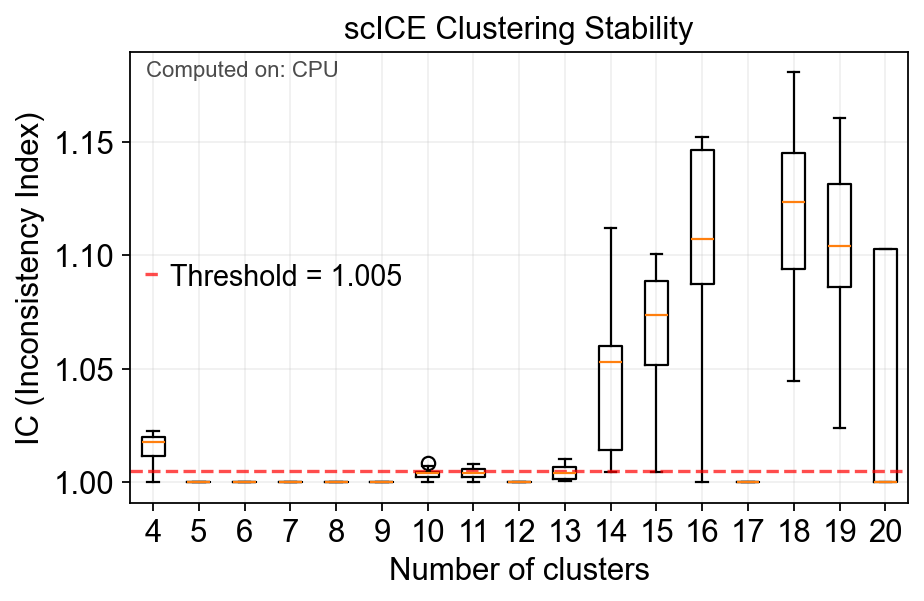
scICE¶
The single-cell Inconsistency Clustering Estimator (scICE) to evaluate clustering consistency and provide consistent clustering results, achieving up to a 30-fold improvement in speed compared to conventional consensus clustering-based methods, such as multiK and chooseR. Application of scICE to 48 real and simulated scRNA-seq datasets, some with over 10,000 cells, successfully identifies all consistent clustering results, substantially narrowing the number of clusters to explore. By enabling the focus on a narrower set of more reliable candidate clusters, users can greatly reduce computational burden while generating more robust results.
Here, you can directly use scICE according omicverse.
model=ov.utils.cluster(
adata,
method='scICE',
use_rep='scaled|original|X_pca',
resolution_range=(4,20),
n_boot=50,
n_steps=11
)
🔧 Device: CPU, Parallel jobs: -1
All required Python packages are properly installed.
Building neighborhood graph...
Converting graph to igraph format...
Starting scICE clustering with CPU...
Exploring 17 cluster numbers: [4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20]
🚀 Using parallel processing: each thread handles one cluster number
🔧 Processing 17 cluster numbers in parallel...
Computing MEI scores...
✅ Completed scICE clustering. Found 17/17 stable solutions.
📊 Average IC score: 1.0289
🎯 Stable cluster numbers found: [4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20]
Added 11 stable clustering solutions to adata.obs
scICE_cluster has been added to adata.obs
fig=model.plot_ic(figsize=(6,4))
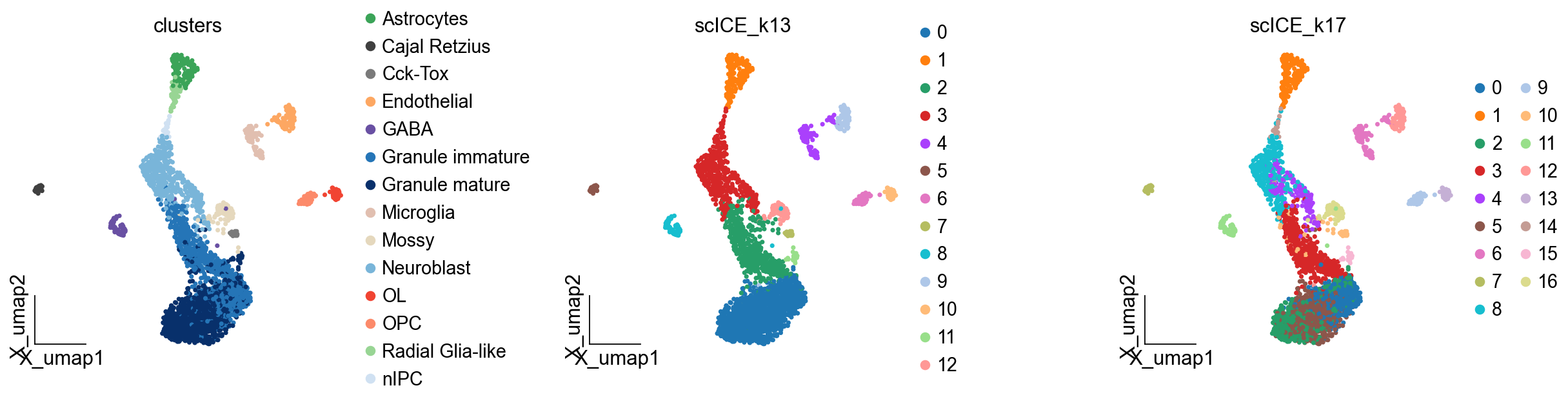
ov.pl.embedding(adata,basis='X_umap',
color=['clusters','scICE_k13','scICE_k17'],
frameon='small',wspace=0.5)
Supervised clustering¶
In addition to clustering using unsupervised clustering methods, we can also try supervised clustering methods, such as Gaussian mixture model clustering, which is a supervised clustering algorithm that works better in machine learning
Gaussian mixture models can be used to cluster unlabeled data in much the same way as k-means. There are, however, a couple of advantages to using Gaussian mixture models over k-means.
First and foremost, k-means does not account for variance. By variance, we are referring to the width of the bell shape curve.
The second difference between k-means and Gaussian mixture models is that the former performs hard classification whereas the latter performs soft classification. In other words, k-means tells us what data point belong to which cluster but won’t provide us with the probabilities that a given data point belongs to each of the possible clusters.
Here, we set method='GMM' to cluster the cells using GaussianMixture,n_components means the PCs to be used in clustering, covariance_type means the Gaussian Mixture Models (diagonal, spherical, tied and full covariance matrices supported). More arguments could found in sklearn.mixture.GaussianMixture
ov.utils.cluster(adata,use_rep='scaled|original|X_pca',
method='GMM',n_components=21,
covariance_type='full',tol=1e-9, max_iter=1000, )
running GaussianMixture clustering
finished: found 21 clusters and added
'gmm_cluster', the cluster labels (adata.obs, categorical)
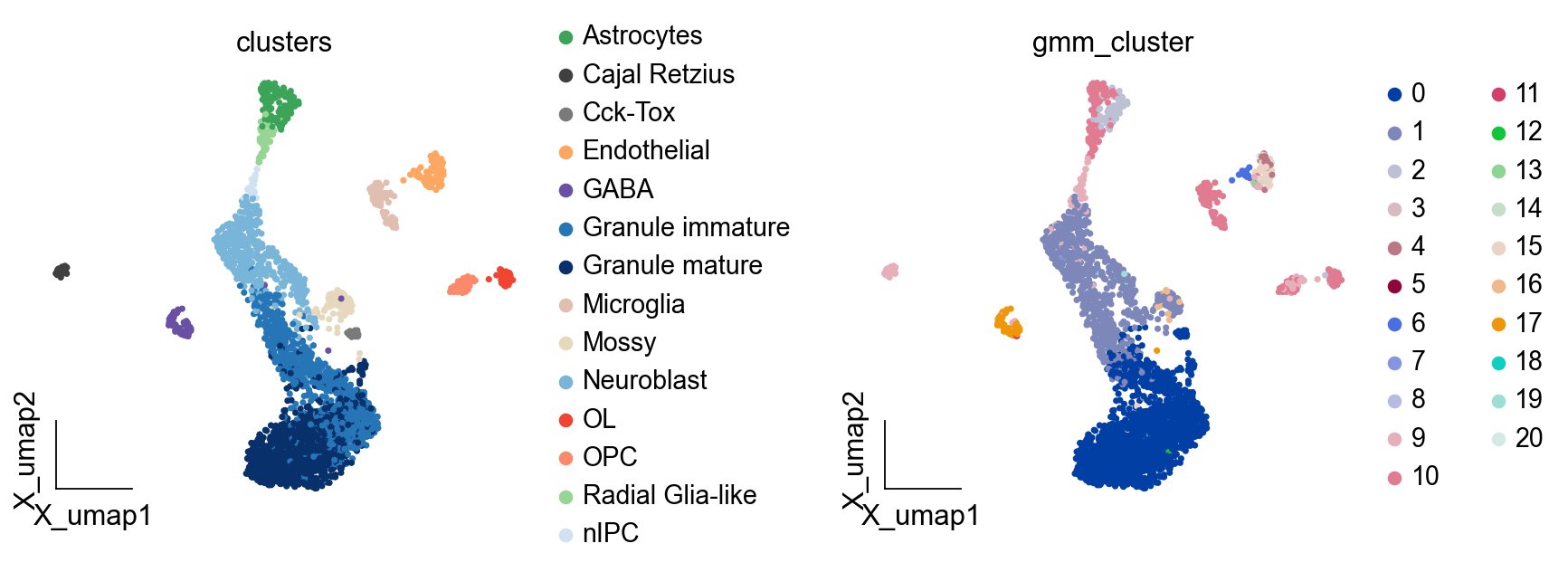
ov.pl.embedding(adata,basis='X_umap',
color=['clusters','gmm_cluster'],
frameon='small',wspace=0.5)
Latent Dirichlet Allocation (LDA) model implementation¶
Topic models, like Latent Dirichlet Allocation (LDA), have traditionally been used to decompose a corpus of text into topics - or themes - composed of words that often appear together in documents. Documents, in turn, are modeled as a mixture of topics based on the words they contain.
MIRA extends these ideas to single-cell genomics data, where topics are groups of genes that are co-expressed or cis-regulatory elements that are co-accessible, and cells are a mixture of these regulatory modules.
Here, we used ov.utils.LDA_topic to construct the model of MiRA.
Particularly, and at a minimum, we must tell the model
feature_type: what type of features we are working with (either “expression” or “accessibility”)
highly_variable_key: which .var key to find our highly variable genes
counts_layer: which layer to get the raw counts from.
categorical_covariates, continuous_covariates: Technical variables influencing the generative process of the data. For example, a categorical technical factor may be the cells’ batch of origin, as shown here. A continous technical factor might be % of mitchondrial reads. For unbatched data, ignore these parameters.
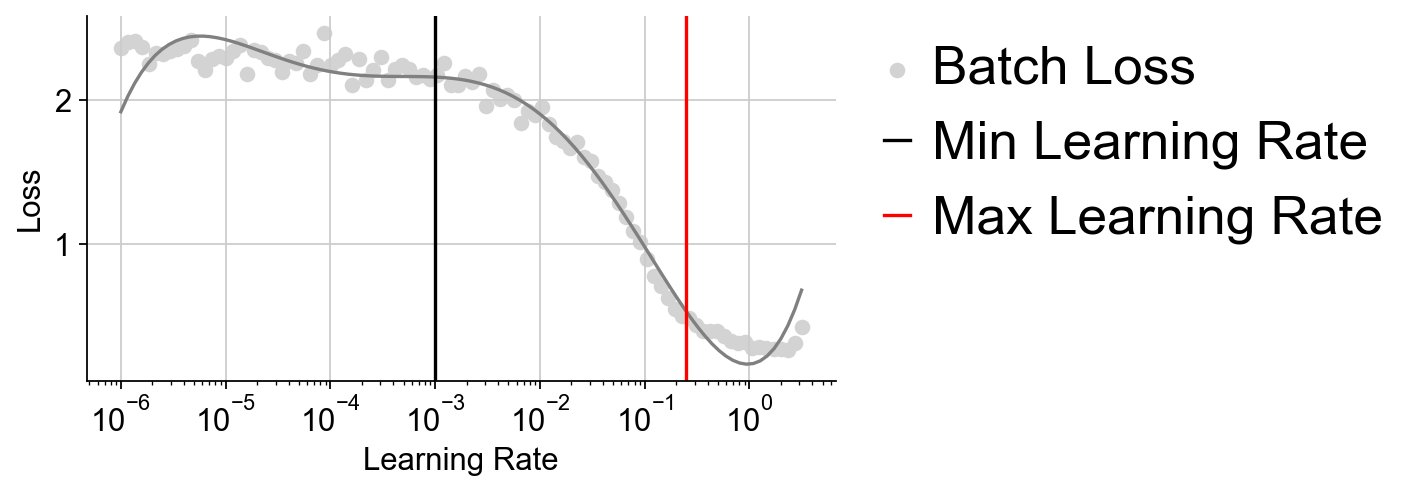
learning_rate: for larger datasets, the default of 1e-3, 0.1 usually works well.
LDA_obj=ov.utils.LDA_topic(adata,feature_type='expression',
highly_variable_key='highly_variable_features',
layers='counts',batch_key=None,learning_rate=1e-3)
mira have been install version: 2.1.0
This method works by instantiating a special version of the CODAL model with far too many topics, which are gradually pruned if that topic is not needed to describe the data. The function returns the maximum contribution of each topic to any cell in the dataset. The predicted number of topics is given by the elbo of the maximum contribution curve, minus 1. A rule of thumb is that the last valid topic to include in the model is followed by a drop-off, after which all subsequent topics hover between 0.-0.05 maximum contributions.
We set NUM_TOPICS to six to try.
LDA_obj.plot_topic_contributions(6)
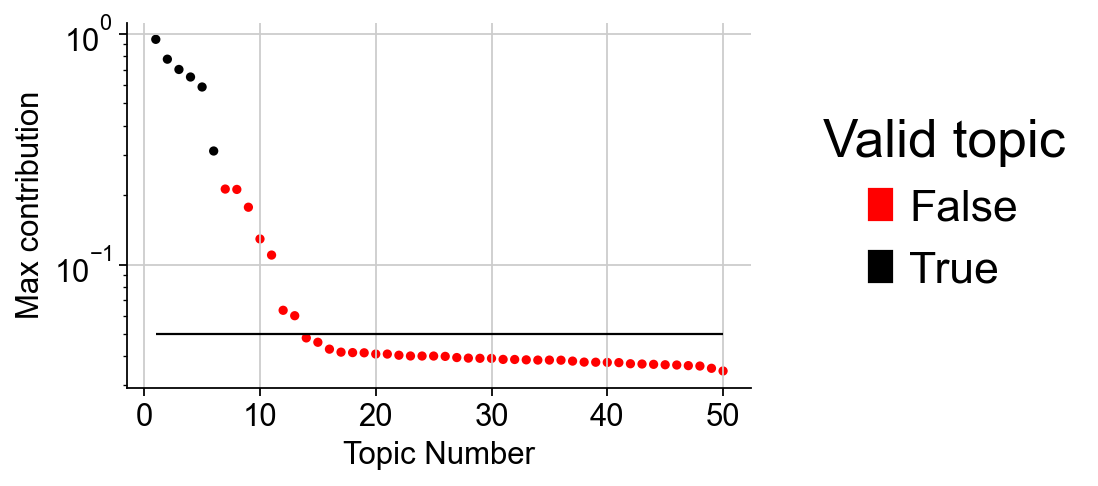
We can observe that there are 13 TOPICs to be above the threshold line, so we set the new NUM_TOPIC to 12
LDA_obj.predicted(13)
running LDA topic predicted
finished: found 13 clusters and added
'LDA_cluster', the cluster labels (adata.obs, categorical)
One can plot the distribution of topics across cells to see how the latent space reflects changes in cell state:
ov.plot_set()
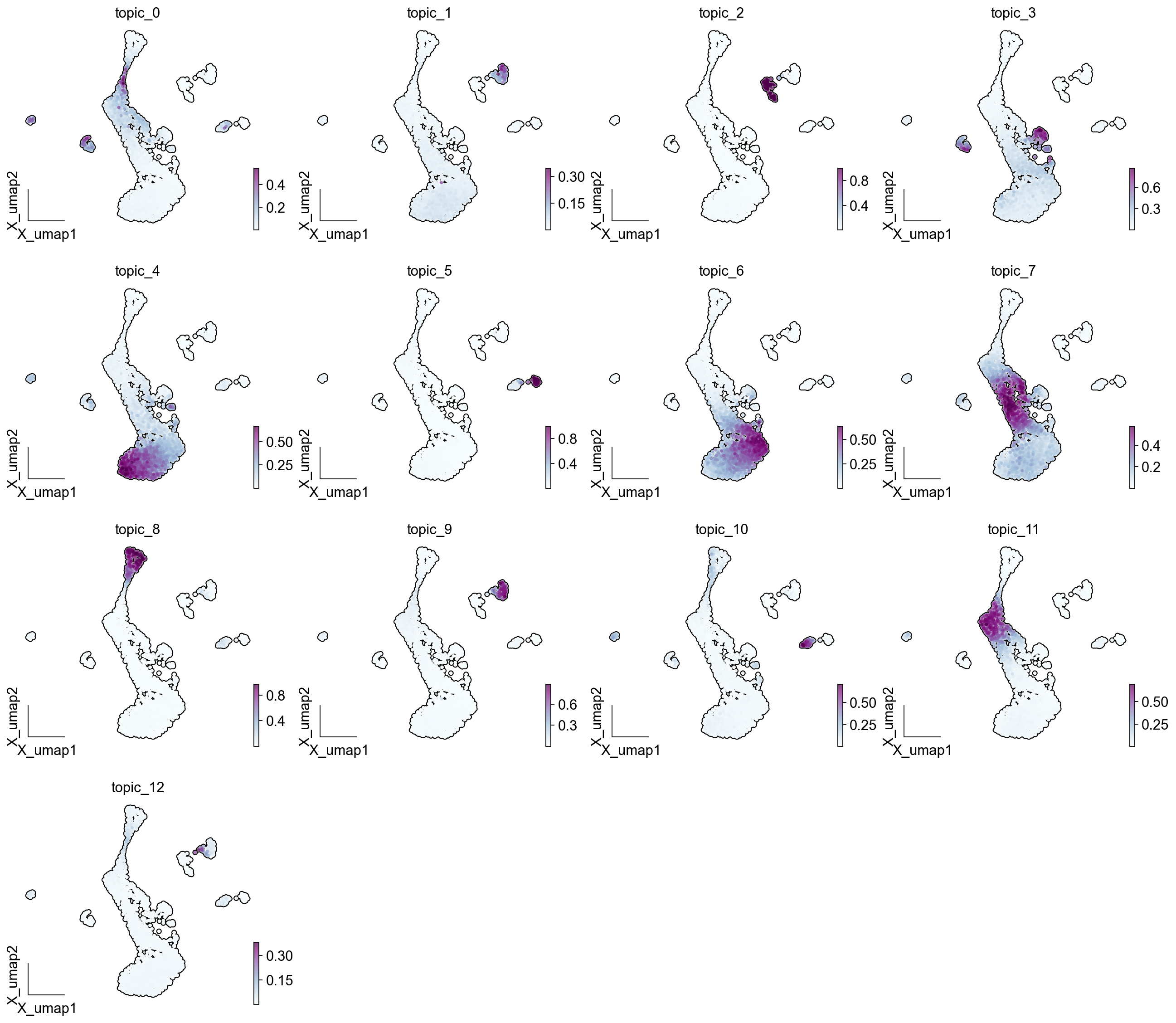
ov.pl.embedding(adata, basis='X_umap',color = LDA_obj.model.topic_cols, cmap='BuPu', ncols=4,
add_outline=True, frameon='small',)
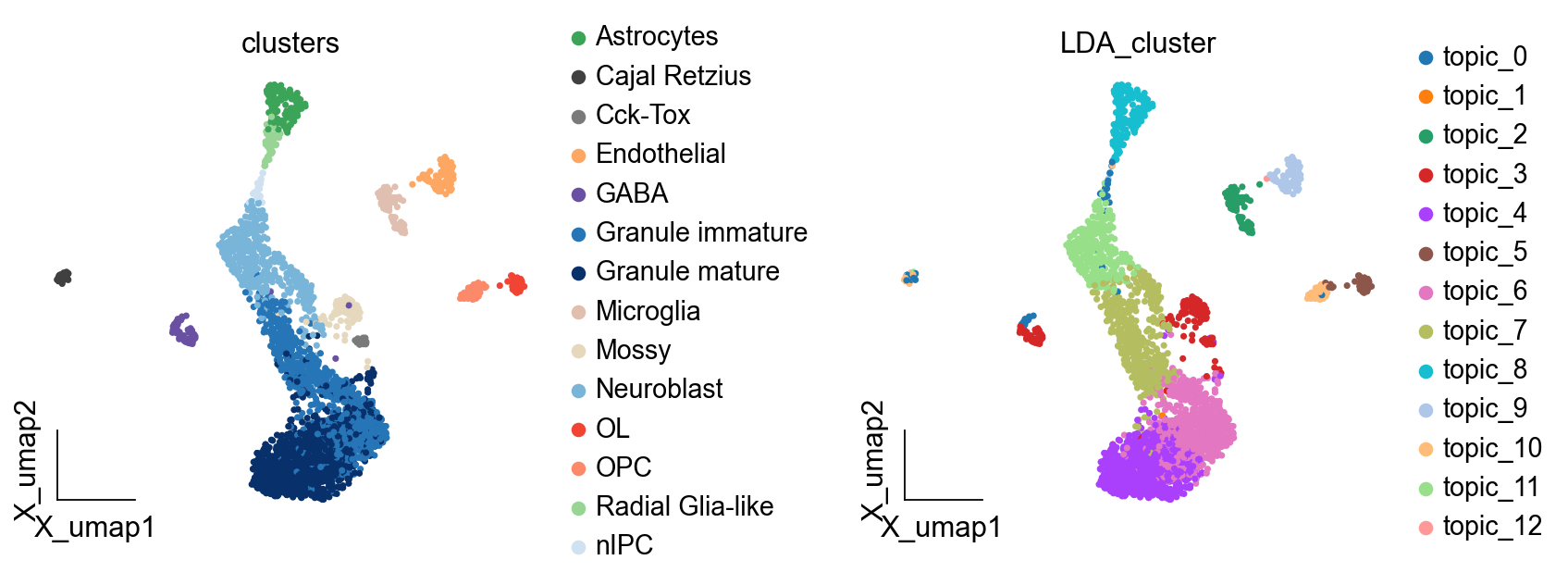
ov.pl.embedding(adata,basis='X_umap',
color=['clusters','LDA_cluster'],
frameon='small',wspace=0.5)
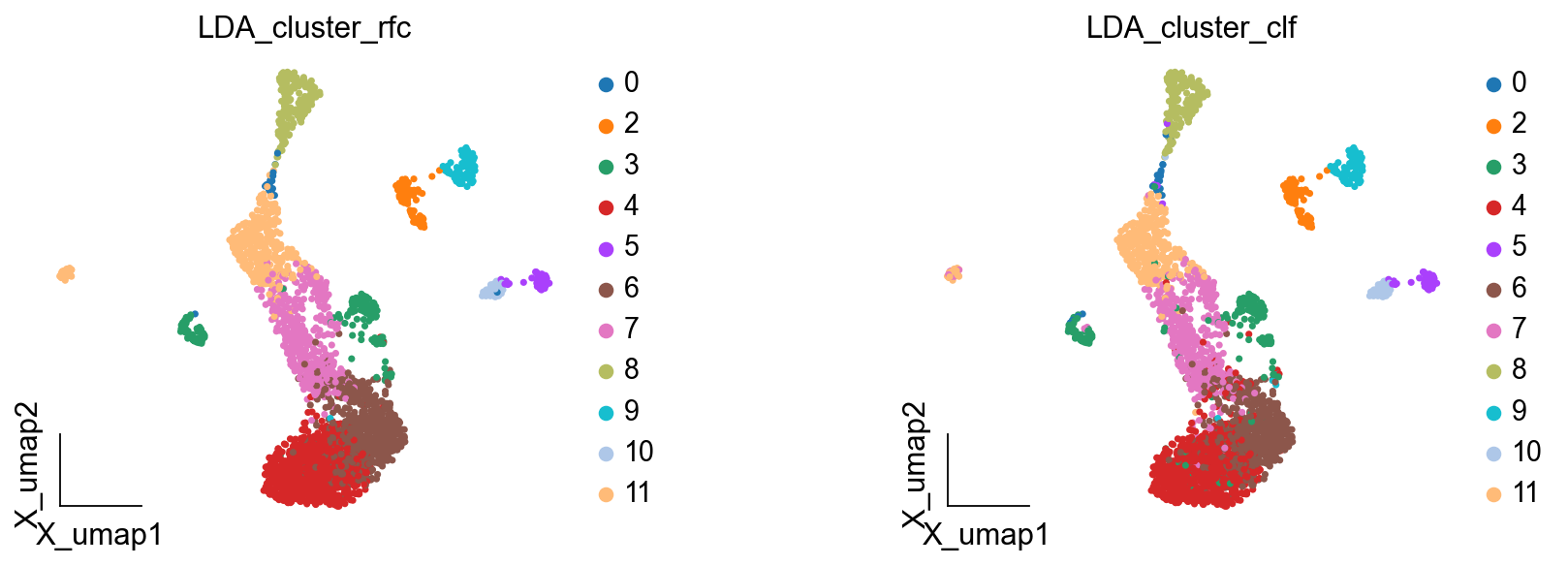
Here we are, proposing another idea of categorisation. We use cells with LDA greater than 0.4 as a primitive class, and then train a random forest classification model, and then use the random forest classification model to classify cells with LDA less than 0.5 to get a more accurate
LDA_obj.get_results_rfc(adata,use_rep='scaled|original|X_pca',
LDA_threshold=0.4,num_topics=13)
running LDA topic predicted
Single Tree: 0.9617940199335548
Random Forest: 0.9883720930232558
LDA_cluster_rfc is added to adata.obs
LDA_cluster_clf is added to adata.obs
ov.pl.embedding(adata,basis='X_umap',
color=['LDA_cluster_rfc','LDA_cluster_clf'],
frameon='small',wspace=0.5)
cNMF¶
More detail could be found in https://starlitnightly.github.io/omicverse/Tutorials-single/t_cnmf/
adata.X.toarray()
array([[5.9377255, 0. , 0. , ..., 8.609415 , 0. ,
0. ],
[0. , 0. , 0. , ..., 7.206903 , 0. ,
0. ],
[0. , 0. , 0. , ..., 8.979355 , 0. ,
0. ],
...,
[0. , 0. , 0. , ..., 8.287922 , 0. ,
0. ],
[0. , 0. , 0. , ..., 8.657587 , 0. ,
0. ],
[0. , 0. , 0. , ..., 9.004353 , 0. ,
5.02186 ]], dtype=float32)
import numpy as np
## Initialize the cnmf object that will be used to run analyses
cnmf_obj = ov.single.cNMF(adata,components=np.arange(5,11), n_iter=20, seed=14, num_highvar_genes=2000,
output_dir='example_dg1/cNMF', name='dg_cNMF')
## Specify that the jobs are being distributed over a single worker (total_workers=1) and then launch that worker
cnmf_obj.factorize(worker_i=0, total_workers=4)
cnmf_obj.combine(skip_missing_files=True)
cnmf_obj.k_selection_plot(close_fig=False)
selected_K = 7
density_threshold = 2.00
cnmf_obj.consensus(k=selected_K,
density_threshold=density_threshold,
show_clustering=True,
close_clustergram_fig=False)
result_dict = cnmf_obj.load_results(K=selected_K, density_threshold=density_threshold)
cnmf_obj.get_results(adata,result_dict)
cNMF_cluster is added to adata.obs
gene scores are added to adata.var
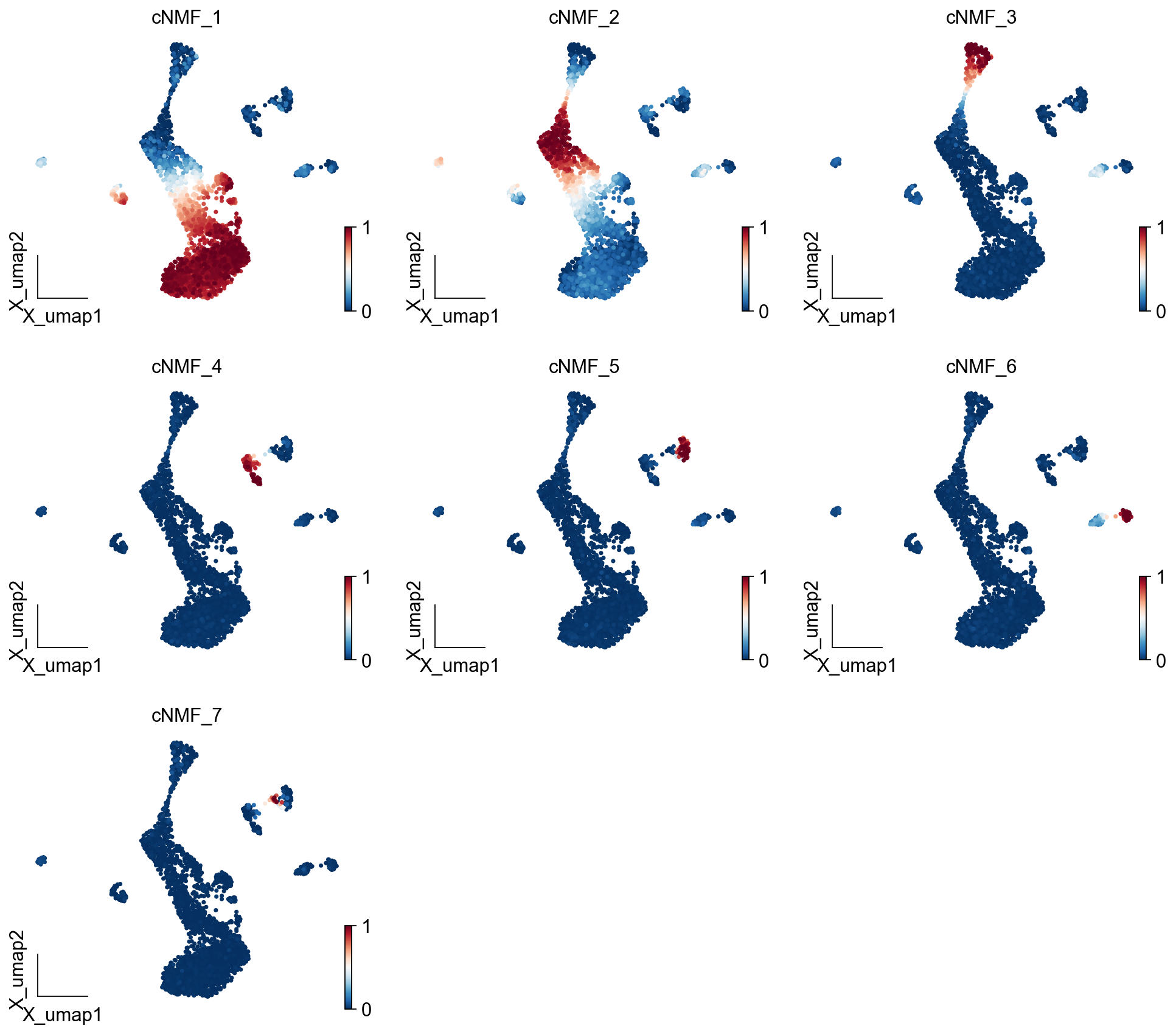
ov.pl.embedding(adata, basis='X_umap',color=result_dict['usage_norm'].columns,
use_raw=False, ncols=3, vmin=0, vmax=1,frameon='small')
cnmf_obj.get_results_rfc(adata,result_dict,
use_rep='scaled|original|X_pca',
cNMF_threshold=0.5)
Single Tree: 0.9905992949471211
Random Forest: 0.9988249118683902
cNMF_cluster_rfc is added to adata.obs
cNMF_cluster_clf is added to adata.obs
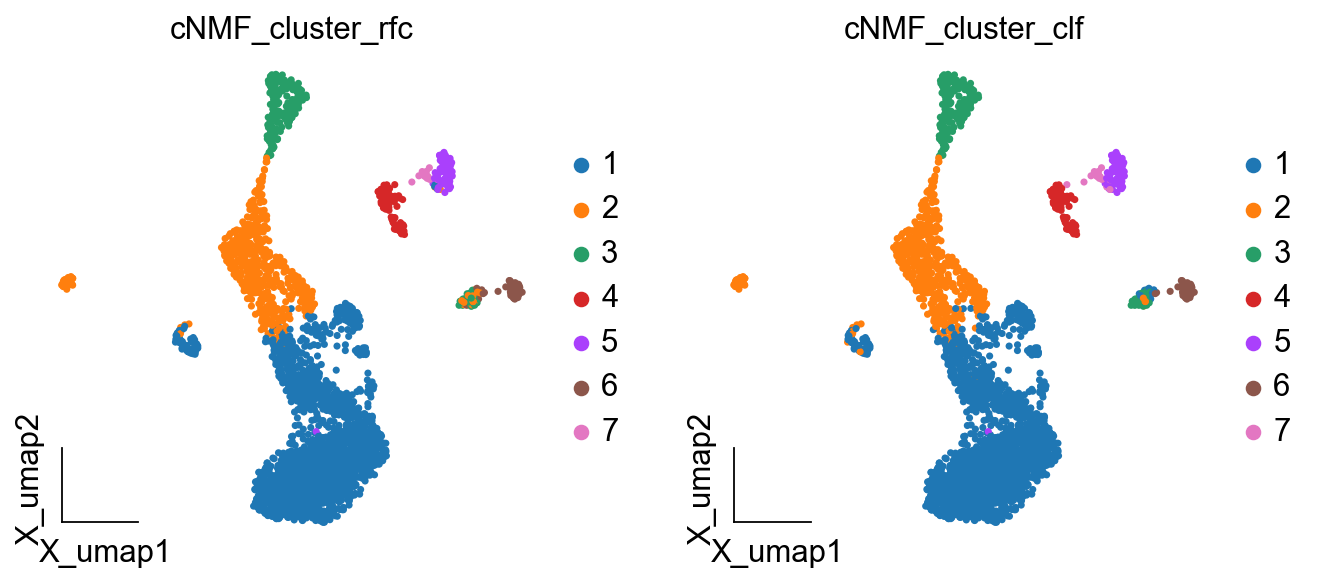
ov.pl.embedding(
adata,
basis="X_umap",
color=['cNMF_cluster_rfc','cNMF_cluster_clf'],
frameon='small',
#title="Celltypes",
#legend_loc='on data',
legend_fontsize=14,
legend_fontoutline=2,
#size=10,
#legend_loc=True,
add_outline=False,
#add_outline=True,
outline_color='black',
outline_width=1,
show=False,
)
[<AxesSubplot: title={'center': 'cNMF_cluster_rfc'}, xlabel='X_umap1', ylabel='X_umap2'>,
<AxesSubplot: title={'center': 'cNMF_cluster_clf'}, xlabel='X_umap1', ylabel='X_umap2'>]
Evaluation the clustering space¶
Rand index adjusted for chance. The Rand Index computes a similarity measure between two clusterings by considering all pairs of samples and counting pairs that are assigned in the same or different clusters in the predicted and true clusterings.
from sklearn.metrics.cluster import adjusted_rand_score
ARI = adjusted_rand_score(adata.obs['clusters'], adata.obs['leiden'])
print('Leiden, Adjusted rand index = %.2f' %ARI)
ARI = adjusted_rand_score(adata.obs['clusters'], adata.obs['louvain'])
print('Louvain, Adjusted rand index = %.2f' %ARI)
ARI = adjusted_rand_score(adata.obs['clusters'], adata.obs['gmm_cluster'])
print('GMM, Adjusted rand index = %.2f' %ARI)
ARI = adjusted_rand_score(adata.obs['clusters'], adata.obs['LDA_cluster'])
print('LDA, Adjusted rand index = %.2f' %ARI)
ARI = adjusted_rand_score(adata.obs['clusters'], adata.obs['LDA_cluster_rfc'])
print('LDA_rfc, Adjusted rand index = %.2f' %ARI)
ARI = adjusted_rand_score(adata.obs['clusters'], adata.obs['LDA_cluster_clf'])
print('LDA_clf, Adjusted rand index = %.2f' %ARI)
ARI = adjusted_rand_score(adata.obs['clusters'], adata.obs['cNMF_cluster_rfc'])
print('cNMF_rfc, Adjusted rand index = %.2f' %ARI)
ARI = adjusted_rand_score(adata.obs['clusters'], adata.obs['cNMF_cluster_clf'])
print('cNMF_clf, Adjusted rand index = %.2f' %ARI)
Leiden, Adjusted rand index = 0.36
Louvain, Adjusted rand index = 0.38
GMM, Adjusted rand index = 0.49
LDA, Adjusted rand index = 0.53
LDA_rfc, Adjusted rand index = 0.54
LDA_clf, Adjusted rand index = 0.51
LDA_rfc, Adjusted rand index = 0.41
LDA_clf, Adjusted rand index = 0.41
We can find that the LDA topic model is the most effective among the above clustering algorithms, but it also takes the longest computation time and requires GPU resources. We notice that the Gaussian mixture model is second only to the LDA topic model. The GMM will be a great choice in omicverse’s future clustering algorithms for spatial transcriptomics.